- Tiempo de lectura: 3 minutos
- Problema: ¿somos demasiado confiados en el aprovisionamiento de infraestructura IT?
- Observación: los proveedores de productos y servicios ITC tenemos ya un alto grado de subcontratación de infraestructura, se trata de un tema crítico que hay que saber gestionar con precisión
- Propuesta: en Savvy Data Systems desde 2010 apostamos por la construcción sobre IaaS en lugar de sobre SaaS, asumiendo más carga de trabajo para el desarrollo pero obteniendo un mayor control
En mi trabajo, uno de mis muchos cometidos es conocer las diferentes Plataformas Cloud que van surgiendo, independientemente de su ámbito de aplicación. Este tipo de tecnologías tiende a ser de aplicación muy trasversal, es por eso que dedico parte de mi tiempo a estudiarlas. No son pocas ya las veces que he tenido la siguiente conversación:
FS -pero, ¿dónde están tus datos?
XX -pues en la nube
FS -vale, en la nube, ¿pero dónde físicamente?
XX -pues eso, en la nube
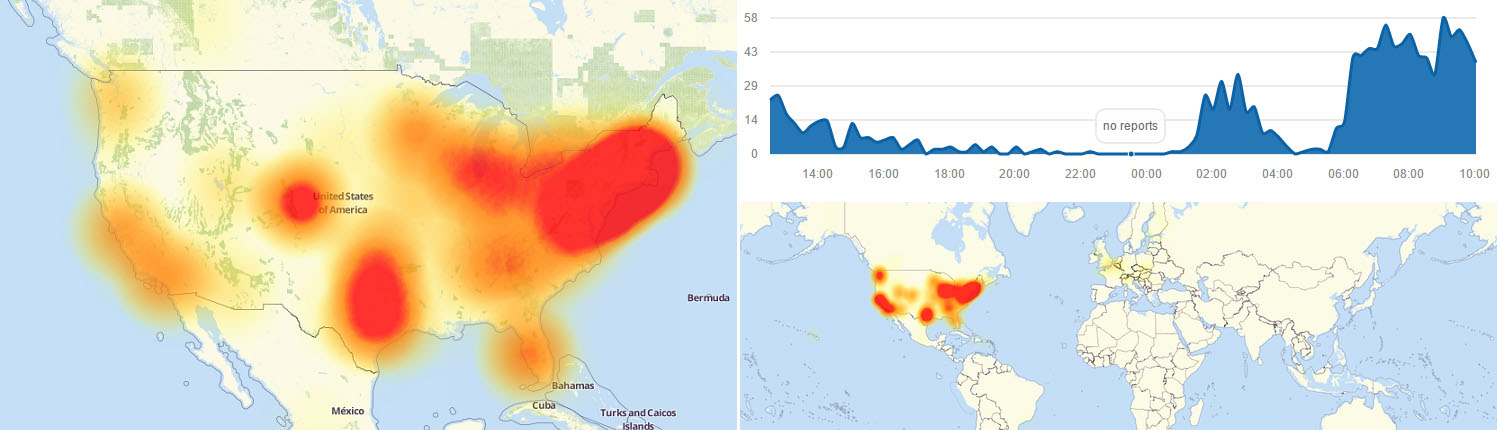
Estamos viviendo una época en la que el outsourcing de infraestructura y servicios IT está irrumpiendo como una locomotora, y yo soy el primero que está a favor de ello. Ahora bien, no podemos cometer el error de basar parte de nuestra política de Ciberseguridad en la confianza ciega hacia el proveedor IT. Pero, ¿qué tienen que ver la confianza, la Ciberseguridad, y el Camino de Santiago?

Una de mis etapas en El Camino